- Orientasi dan perkenalan (Tuesday, 14 Sept 2021) 09.00-10.40
Postingan ini akan mengantarkan pembaca pada pengalaman saya selama satu semester dalam mengambil mata kuliah New literacies, content analysis, and text mining di Institute of Learning Sciences and Technologies National Tsing Hua University Fall Semester 2021. Mata kuliah ini 3 sks dengan pengampu Prof. Su-Yen Chen. Background pendidikan beliau S1 dari History NTU, kemudian master dan PhD di University of Texas at Austin: Austin, TX, US dengan bidang Curriculum and Instruction masih berhubungan dengan bidang saya khususnya waktu di S1. Profil beliau selengkapnya dapat diakses melalui https://nthuilst.wixsite.com/suychen sedangkan profil publikasinya dapat dilihat dari profil ORCIDnya.
Pada mata kuliah ini kami akan belajar tentang new literacy, content analysis, dan text mining pada topik yang diminati. Ada tiga indikator yakni kehadiran dan partisipasi dikelas 20%, selected paper dan discussion 45%, dan final project berbasis kelompok 35%. Untuk final project akan melakukan praktik text mining pada sejumlah data set khususnya dari infromasi dan berita yang tersebar di US berkaitan dengan Covid-19. Untuk mendukung final project kami akan belajar beberapa tool dan software seperi Phyton, Anaconda, Jupyterlab and Jupyter Notebook. Hal ini akan menjadi tantangan tersendiri bagi saya sekaligus akan menjadi pengalaman baru untuk bekal pasca lulus dari kuliah ini.
2. Concept of New Literacies (Tuesday, 05 Oct 2021) 09.00-12.00
Hari ini kuliah pertemuan ke dua walaupun sudah masuk pekan ke empat, karena dua minggu lalu kami ada dua libur nasional yakni moon festival dan teachers day. Hari ini agenda kuliah dilakukan secara tatap muka di ruang 4.10. Dua jam pertama diisi dengan penyajian materi dari professor tentang definition, concept, karakteristik dan contoh-contoh tentang new literacies, content analyisis, and text mining. Pada jam ketiga giliran salah satu teman kami mempresentasikan hasil bacaan pada materi yang telah disediakan untuk setiap pekannya.
Secara sederhana new literacies dimaknai sebagai kompetensi lanjutan dari literacy yang selama ini diketahui bersama. Literacy selama ini dimaknai kemampuan untuk membaca, menulis, mendengar dan berbicara. Empat keterampilan ini sudah sangat familiar disemua jenjang pendidikan karena menjadi inti dari proses pembelajaran itu sendiri disamping menghitung, menganalisis dan sebagainya. Namun new literacies dimaknai lebih jauh dari sekedar litearcy, karena tujuannya adalah membuat seorang mampu memahami konteks informasi yang diperoleh untuk kepentingan hidup. New literacies memiliki tujuan lebih jauh, ketika literacy yang diartikan sebagai reading ability maka yang disasar adalah kemampuan untuk membaca dan memahami isi teks, walaupun terkadang sulit menangkan konteks dari teks yang dibaca. Sehingga posisi pembaca hanya sebagai consumen dari informasi yang disediakan oleh para produsen. Sedangkan pada new literacies, maka setiap orang berperan sebagai procon, artinya sebagai produsen sekaligus sebagai konsumen. Dengan demikian pembaca dan penulis sama-sama membangun makna dari konteks informasi.
Pada kesempatan ini saya bertanya dua hal, pertama apa keterampilan yang harus dikuasai oleh siswa untuk menguasai new literacies, karena kalau hanya kemampuan membaca seperti reading comprehension, skiming, dan lain-lain sepertinya itu lebih ke keterampilan pada konteks traditional literacy. Professor menjawab, selain menguasai keterampilan untuk menangkan makna dari informasi, maka kita harus juga menguasai cara untuk memperoleh informasi secara cepat, mengolahnya secara tepat, dan menyampaikannya/mengkomunikasikannya secara efektif kepada audiens. Dengan demikian penggunaan teknologi sangat penting, baik dalam proses pencarian dan pemerolehan informasi, maupun dalam proses pengolahan dan penyajian dan publikasi informasi.
Pertanyaan kedua tentang perbedaan content analysis, discourse analysis, dan meta analysis yang saya ajukan setelah professor menjelaskan tentang konsep dan karakteristik content analysis. Beliau menjawab content analysis bisa maknai sebagai salah satu metode untuk menganalisis isi informasi baik dari media cetak, maupun online termasuk media audio dan lain-lain. Sedangkan discourse analysis merupakan bagian dari content analysis, contohnya ketika digunakan untuk menganalisasi wacana dan argumentasi dari para responden, biasanya discourses analysis banyak digunakan untuk analisis teks. Sementara meta analysis merupakan salah satu metode penelitian kuali dan kuanti yang dilakukan untuk menganalisis lebih jauh dari suatu penelitian pada suatu topik tertentu. Misalnya ingin mengetahui metode terbaik yang digunakan untuk melatih new literacies pada siswa, maka dapat dilakukan pengumpulan hasil penelitian tentang topik tersebut pada semua jenjang dan jalur pendidikan dari berbagai belahan dunia, kemudian fokus menjadi dampaknya dan mengelompokannya berdasarkan kesamaan treatment yang dilakukan, kemudian menggunakan teknik analisis statistik tertentu untuk mengetahui rata-rata dampak paling tinggi dari hasilnya. Sehingga dapat ditemukan rekomendasi metode terbaik yang dapat digunakan oleh para praktisi. Sebenarnya saya masih ada satu pertanyaan lain yang tidak sempat ditanyakan karena keterbatasan waktu yakni tentang bagaimana para guru di Taiwan dipersiapkan sebelum menjadi guru dan bagaimana program pengembangan profesionalismenya, sehingga siswa-siswa di Taiwan memiliki rangking asesmen international yang tinggi seperti PISA, TIMSS maupun PIRLS. Mudah-mudahan minggu depan ada kesempatan untuk bertanya.
3. Literacy Studies in School and University (Tuesday, 12 Oct 2021) 09.00-12.00
Hari ini memasuki pertemuan ketiga, sesuai jadwal pada silabus, hari ini ada empat mahasiswa yang bertugas untuk mempersentasikan hasil kajian terhadap paper yang telah dipilih sejak pertemuan pertama. Saya termasuk salah satunya selain Aby, Sheryl, dan Andy. Pada urutan pertama ada Aby yang mempersentasikan makalah dengan judul Mapping today's literacy landscapes: Navigational tools and practices for the journey. Journal of adolescent & adult Literacy, 57(2), 131-140. Semetara itu saya memilih judul Digital storytelling for 21st-century skills in virtual learning environments. Creative Education. Sedangkan Sheryl mempersentasikan paper dengan judul The development of shared liking of representational but not abstract art in primary school children and their justifications for liking. Frontiers in human neuroscience, 10, 21. Dan terakhir Andy mempersentasikan artikel dengan judul Analytics to literacies: The development of a learning analytics framework for multiliteracies assessment. International Review of Research in Open and Distributed Learning, 15(4), 284-305.
Semua paper hari ini membutuhkan penalaran yang mendalam bagi kami para petugas dan teman kelas yang menyimaknya. Artikel pertama menjelaskan tentang navigator cara mengaruni samudra pengetahuan dan informasi yang sangat luas. Sedangkan artikel yang saya jelaskan tentang DST yang dapat digunakan untuk melatih 21st century skill dilaporkan oleh peneliti di Finland, Greece dan USA. Sedangkan artikel ketiga yang dipresentasikan oleh Sheryl menjelaskan tentang bagaimana anak-anak memahami pesan dari lukisan abstrak. Ini paper mengandung banyak istilah dan terminologi baru, namun bagus untuk membuka wawasan tentang bidang seni lukis ditinjau dari riset yang cukup menarik. Sementara itu Andy menjelaskan tentang framework empiris dari model learning analytics.
Setelah masing-masing mempresentasikan makalahnya, kemudian kami berdiskusi sesuai dengan topik masing-masing. Saya membagi teman kelas menjadi 3 kelompok dan masing-masing kelompok mendiskusi tentang metode belajar yang dapat dilakukan untuk mengajarkan minimal 2 keterampilan belajar abad 21 menggunakan form online agar memudahkan proses pengisiannya.
4. Literacy studies research in reading and writing (Tuesday, 19 October 2021) 09.00-12.00
Kuliah hari ini dimulai dengan penjelasan umum tentang gambaran 4 artikel yang akan dibahas oleh masing-masing mahasiswa. Pekan ini topik kuliah kami masih seputar new literacy. Artikel pertama disajikan oleh Eric dengan judul Text navigation in multiple source use yang ditulis oleh Alexandra List, Patricia A. Alexander. Artikel ini menggunakan Information foraging theory yang artinya kurang lebih, ketika kita membaca sesuatu, maka kita akan berpindah ke bacaan lain jika dipandang yang kita baca sudah cukup dipahami, atau sulit dipahami sehingga tidak memndapatkan apa-apa. Ada beberapa jenis navigasi antara lain limitied, primary, distributed, discrimating and other navigation. Ada 4 alokasi waktu untuk membaca, yakni total time, average time, standar time and amount time. Revisit untuk kembali membaca naskah akan membuat kita lebih memahmi isi bacaan. Ada dua klasifikasi teknik bacaan, pertama sampling, kedua satisficing. Agenda paling akhir di isi dengan diskusi apa yang menjadi pertimbangan kami masing-masing dalam memilih artikel untuk dipresentasikan dalam satu semester.
Artikel kedua disajikan oleh Winy berjudul Multiple-documents literacy: Strategic processing, source awareness, and argumentation when reading multiple conflicting documents yang ditulis oleh Øistein Anmarkrud, Ivar Bråten ⁎, Helge I. dari Norwegia. Ada 4 menttal represenation dari multiple yakni text model, situatuion model dari Kintsch single tect comprehension, dan multiple comprehension yakni intertext model dan mental model. Selain itu ketika kita membaca maka ada tiga kategori yakni identifying and learning important information, kedua monitoring dan evaluating. Bagaimana melatih siswa untuk evaluasi trusworthiness text, ketika mereka memiliki keterbatasan informasi dan knowledge. mungkin ga ada dampak kelelahan setelah membaca beberapa artikel? sehingga justifikasinya tidak lagi objektif?. Setelah agenda presentasi, kami secara berkelompok diminta untuk melakukan brain storming untuk memilih topik yang kontroversial yang dapat diajarkan kepada siswa. Ada yang mengangkat topik tentang partai politik dan nuklir.
Artikel ketiga disajikan oleh Abby dengan judul: Toward a Professional Development Model for Writing as a Digital, Participatory Process artikel ini menjelaskan tentang pengembangan profesi (PD) guru untuk melatih kemampuan mengajar menulis dalam konteks digital. Artikel dimulai dengan multiple contradictions antara teori dan pratice, needed training vs available training, conflicting perspective. Saya penasaran apakah ada khusus bagi guru di Taiwan untuk ikut PD dan meningkatkan profesionalismenya, dan dalam bentuk apa? berapa lama? . Selanjutnya menjelaskan tentang 11 keterampilan dalam konteks new media literacy (NML). Untuk menjawab pertanyan risetnya, peneliti menggunakan metode formative experiment. Subjek penelitian sebanyak 15 guru kelas 4 dan 5 SD. Menggunakan interview dan observation untuk mengukut gambaran awal. Kemudian ada 4 hari workshop untuk mendiskusikan model pembelajaran, elemen kurikulum kepenulisan, dan tool yang digunakan, dan terakhir menggunakan collaborative to design a inquiry. Hasilnya menunjukkan bahwa kurang data tentang contoh kemampuan siswa menulis, dan kegiatan menulis kurang terperhatikan dalam standar kurikulum yang ada. Akhirnya guru dapat berkembang kemampuannya dan menggunakan teknologi untuk melatih siswa mengajar, namun mereka lupa untuk memiliki alasan mengapa menggunakan teknologi tersebut. Kami mendesain kelas menulis blogging, pertama merencanakan main isu yang diposting di blog, how to find the information and data to write it, and how to write it based on the deadline, and how to evaluate the content, and how to maintenance and makesure our blog will continuity, how to design interesting blog.
Artikel keempat hari ini disajikan oleh Shery berjudul Students’ Attitudes to Information in the Press: Critical Reading of a Newspaper Article With Scientific Content. Di bagian awal penyaji menjelaskan tentang kerangka teori yang digunakan seperti argumentation, validity and reliability data dalam menyajikan informasi. Dalam praktik di pembelajaran, guru harus mendesain situasi belajar yang mendukung topik yang dibahas. Untuk melatih membaca siswa, maka kita dapat menunjukkan dulu judul dan ide pokok atau kata kunci dari bahan bacaan. What is the associated factor influeced that 3 types of readers? and how to train student to be a critical reader?. Kita harus mendesain tahapan kegiatan sebelum membaca, ketika membaca, dan setelah membaca. Pada tahap akhir kami berdiskusi tentang profil type masing-masing dalam membaca. Secara umum kami sepakat bahwa tipe pembaca akan dipengaruhi oleh jenis bacaan. Jika kita membaca artikel dari jurnal yang bagus, maka kita dapat menjadi tipe pertama yakni yang memandang informasi dan data yang disajikan kecil kemungkinan salah, karena sudah melewati tahap review dari editor dan reviewer. Hal ini juga terjadi ketika kita membaca sesuatu yang baru, dan kita tidak memiliki prior knowledge yang cukup sebelumnya, sehingga cenderung akan mengikuti saja tanpa melakukan upaya untuk menolak idenya. Sedangkan untuk jenis bacaan artikel di media masa yang bersifat opini dari penulisnya maka kita dapat menjadi tipe ideological reader atau critical reader. Demikian juga ketika kita membaca informasi tentang sebuah produk maka kita akan cenderung menjadi critical reader untuk memastikan apa yang akan kita beli benar-benar sesuai kebutuhan dan dapat memuaskan keinginan kita.
5. Literacy studies research in reading and writing (Tuesday, 26 October 2021) 09.00-12.00
Hari ini kuliah pertemuan kelima, polanya seperti minggu lalu, ada 4 presenter yang menyajikan hasil bacaaan dan analisisnya terhadap paper yang ditugaskan. Paper pertama berjudul "The value of social media: are universities successfully engaging their audience?". Artikel ini menjelaskan tentang bagaimana perguruan tinggi di US pada tahun 2012 mengelola sosial media mereka untuk berkomunikasi dengan para audiennya. Mereka menggunakan Content analysis dengan unit analisis adalah akun facebook, twitter, dan youtube dari 30 perguruan tinggi negeri dan swasta di US berdasarkan Top 5, Midle 5 dan bottom 5. Hasilnya mereka rata-rata memiliki akun sosial media dan digunakan untuk branding lembaga, namun mereka masih lemah dalam proses engagement dengan para audien, misalnya jarang membalas komen. Pada sesi akhir kami membuat mini content analysis untuk melihat eksitensi sosial media instagram universitas di Indonesia.
Artikel kedua berjudul "A Three-Step Data-Mining Analysis of Top-Ranked Higher Education Institutions’ Communication on Facebook" yang disajikan oleh Huta. Artikel ini menjelaskan tahapan text mining pada konteks sosial media facebook di kampus-kampus yang bagus di dunia. Mereka melakukan komparasi data tentang waktu mereka posting, bagaimana mereka berkomunikasi, sentimen analisis dari komentar audien, dan juga prediksi untuk postingan berikutnya. Namun hanya mampu memprediksi 3-4 hari ke depan. Karena data set mereka tidak banyak. Pada sesi akhir kami mendiskusikan tentang bagaimana sosial media NTHU dalam mengelolanya.
Artikel ketiga berjudul "A content analysis of top-ranked universities’ mission statements from five
global regions oleh Tuncay Bayrak. yang disajikan oleh Winnie Wu. Artikel ini membahas tentang pernyataan visi misi top 50 perguruan tinggi di berbagai region, seperti Asia, Afrika, Eropa, Amerika latin, Amerika utara. Prosesnya menggunakan content analysis menggunakan Mission statement, text prashing, text filter, and text cluster. Hasilnya masing-masing university pada masing-masing region memiliki karakteristik yang berbeda dalam menyatakan visi dan misinya. Misalnya di Asia kita banyak fokus pada community, and parthnership, sedangkan di US mereka lebih banyak bicara tentang Idea dan riset. Pada sesi terakhir kami berdiskusi jika kami membaut university, apa visi, goal dan slogan yang akan kami gunakan.
Artikel keempat berjudul: New literacy practice in a facebook group: The case of a residential
learning community dari Su-Yen Chen∗, Hsin-Yu Kuo, T.C. Hsieh. Penulis pertamanya adalah profesor kami yang mengajar di kelas ini. Artikel ini menjelaskan tentang pemanfaatan FB untuk mendukung pembelajaran. Ada 4 pertanyaan penelitian yang dikaji. Ada 5 jenis social learning analytics, antara lain social network, content, discourse, disposition,and context analyitis. menggunakan beberapa data seperti post ID, author ID, the message, post media tipe, number of likes, niumber of comments, creation time, total ada 7.396 posting. 5 new literacy indikator such as fun, performance, appropriation, play, collective intellegence diambil dari 10 new literacy skill/practice. Pada sesi akhir kami berdiskusi tentang platform yang paling kami sukai untuk kami gunakan sebagai learning environtment. Kami memilih google classroom karena memiliki paket lengkap dari semua layanan google.
6. Workshop 1 phyton (Tuesday, 02 November 2021) 09.00-12.00
Agenda kuliah hari ini kami belajar menggunakan aplikasi anaconda dengan jupiter untuk berlatih menggunakan Phyton yang sudah diminta untuk diinstal sebelum pertemuan kuliah hari ini. Selain itu pada hari ini kami diberikan beberapa sumber belajar baru antara lain: https://www.codecademy.com/, kemudian https://spacy.io/usage untuk praktik 2, dan https://universaldependencies.org/. Hari ini ada beberapa materi dan latihan yang diajarkan. Mulai dari basic perintah umum dalam Phyton sampai materi tentang segmentation dari semua data set.
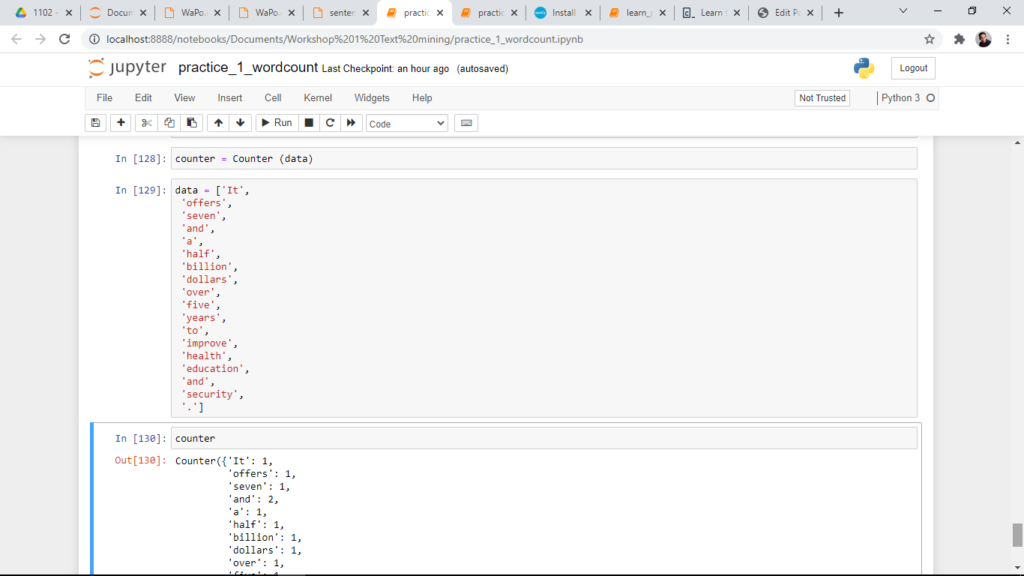
Segmentation dapat digunakan untuk membuat segmentasi data, misalnya mencari jumlah frekuensi suatu data kemudian membuat grafik dari data yang muncul. lalu melihat sebaran datanya. Sehingga data yang awalnya berupa data set berbasis text ataupun angka akan dapat dikembangkan menjadi data berbasis visual, grafik, dot, dan lain-lain. Minggu depan kami kembali melanjutkan presentasi makalah dan workhop akan dilanjutkan tanggal 23 November 2021.
7. Content Analysis in Image (Tuesday, 9 November 2021)
Agenda hari ini kembali ke model kuliah seperti biasanya, ada empat presenter, pertama Yuta yang mempresentasikan paper dengan judul A Deep Learning Perspective on Beauty, Sentiment, and Remembrance of Art. Penulis menggunakan model CNN untuk mengalisis images. Peneliti menggunakan komparasi antara hasil model menggunakan deep learning dengan anotated/prediction dari human rating score. Secara umum ada 6 tahap riset yang dilakukan oleh peneliti. Pertama setup dataset, data set mereka diperoleh dari WikiArt.org yang memiliki datase yang memadai dan memudahkan untuk klasifikasi. Tigas domain yakni aesthetic (JenaAesthetic) yang terdiri dari aesthetic quality, beauty, color, content, composition, sentiment images menggunakan MART, and memorability. CNN model bertujuan untuk mengekstraksi high level images, dan 3 domain tersebut di atas. Dengan menggunakan 8 atribut, seperti content, object, lighting, color, symmetry, repetition, role of thirds, and object emphases.
Hasil penelitian menunjukkan bahwa pada dimensi aestetic maka bright and intense color sangat berpengaruh pada unsur kecatikan gambar, sedangkan pada sentimen maka yang berwarna ebi cerah lebih positif, yang gelap lebih negatif, selain itu juga dari gambarnya, untuk gambar banyak bunga, lebih ke positif, sedangkan untuk memorability maka gambar pemandangan lebih memorable, dibandingkan gambar yang abstrak yang acak. artikel ini sangat menarik karena menggabungkan data hasil analisis menggunakan deep learning dan manusia.
Artikel kedua berjudul WikiArt Emotions: An Annotated Dataset of Emotions Evoked by Art, artikel ini mengkaji sebanyak 200 gambar pada 4 kategori era lukisan. Secara umum emosi sentimen yang muncul ada tiga yakni positif, negatif dan netral atau mixed. Cara pengumpulan datanya menggunakan kuesioner berdasarkan masing-masing aspek. Menggunakan tiga skenario yakni memunculkan gambar, kemudian judul, dan art. Simpulannya judul pada lukisan berpengaruh terhadap emosi. Gambar sedih lebih disukai daripada gambar marah.
Artikel ketiga berjudul ArtEmis: Affective Language for Visual Art yang dipresentasikan oleh Abby. ArtEmis merupakan terminologi perpaduan antara Art and emotions. Artikel ini menarik karena melibatkan lebih dari 6ribu anotator, 80 lukisan dan lebih dari 10 ribu jam proses pengisiannya. Artikel ini menggabungkan human dan maching dalam membuat effective explanation tentag visual art.
Artikel keempat berjudul Understanding and Creating Art with AI: Review and Outlook yang dipresentasikan oleh Winy. Artikel ini menjelaskan tentang kegunaan AI dalam berbagai dimensi kehidupan, dan dijelaskan juga challenge of AI. Artikel ini menjelaskan tentang bagaimana memahami lukisan menggunakan AI. AI juga dapat digunakan untuk membuat lukisan. Aritkel ini menggunakan CNNs (convolutional neural networks) dapat berupa feature extractor (classifi artistice style), object detector (detect object and its position), and similarity judge (content matching). Selain itu juga dijelaskan konsep multimodal untuk memperkaya model AI yang dikembangkan dan digunakan.
Ada beberapa model AI untuk bidang lukisan pertama adalah GANs tahun 2014 untuk membedakan lukisan asli atau palsu menggunaakan discriminator network. Kedua adalah deep dreams yang dikembangkan oleh Goolge untuk mendeteksi lukisan abstrak. Ketiga NST (neural style Transfer), Keempat AICAN (AI Creative Adversarial Network untuk menggabungkan dan membuat new style dari ribuan style yang telah ada sebelumnya. Kelima adalah DALL-E yang membuat image dari deskripsi text, menggunakan text image pairs. Noveltyof AI art karena inovasi, menggunakan computer animation, dan pelukis tidak harus banyak mengontrol. AI hanya mimik perilaku manusia tidak memiliki atribusi manusia seperti kecerdasan dan emosi. Agenda paling akhir hari ini kami membagi kelompok dan berdiskusi untuk project tugas akhirnya. Kami memutuskan untuk mengkaji sentimen analysis siswa dalam praktik pembelajaran sebagai dampak Covid.
8. Text mining (Tuesday, 16 November 2021)
Hari ini kuliah dimulai dengan penyajian data set dari TA yang akan digunakan untuk proyek akhir masing-masing kelompok kami. Kami diperlihatkan data dari new report berbahasa Inggris. Setelah itu professor menjelaskan sepintas gambaran perkuliahan dan empat paper yang akan dipresentasikan pada hari ini. Paper pertama berjudul Social network analysis of COVID-19 sentiments: Application of artificial intelligence dipresentasikan oleh Hendrik. Paper ini menjelaskan tentang sentimen anailisis dari US people pada bulan April 2020 sejak pandemi bermula. Data setnya sekitar 1 juta karena durasinya hanya satu bulan. Namun cukup menarik mereka menggunakan LDA method untuk menganalisis. Ada beberapa kategori yang muncul dalam paper tersebut seperti health care envirionent, bisnis, economi, sentimen analysis, dan lain-lain.
Sedangkan paper kedua berjudul Investigating COVID-19 News before and after the Soft Lockdown: An Example from Taiwan dipresentasikan oleh Sheila Chang. Paper ini ditulis oleh salah satu lab member dari profesor termasuk ada nama professor sebagai coresponding authornya. Paper ini membahas isu pada media di taiwan. Metodenya sama menggunakan LDA. Ada empat pertanyaan penelitian yang diajukan seperti sentimen analysis, respon dari pemerintah.
Artikel ketiga berjudul Finding users' voice on social media: An investigation of online support groups for autism-affected users on Facebook yang dipresentasikan oleh Casy. Artikel ini membahas tentang text mining pada group autis di facebook. Ada hubungan antara authism dengan masalah emosi seseorang. Anggota grupnya ada sekitar 50 grup FB tentang autism. Menggunakan bahasa inggris. Mereka j juga menggunakan LDA dan LDA model evaluation. Hasilnya muncul beberapa kategori pada masing-masing grup. Beberapa topia antara lain parenting, education, family, experience, welcome message, terapi, training and workshop, event and visit, greeting, support, conference, help request. Salah satu yang perlu diperhatikan untuk riset bidang sosial media khususnya untuk grup sosial media, adalah etical isu.
Paper keempat berjudul Mining news media for understanding public health concerns dipresentasikan oleh Yugha. Penelitian dilakukan selama 1 tahun pada 2017 tentang masalah public healts issues. Menggunakan MeSH term, kemudian menggunakan Phyton script untuk mencari tahu term yang banyak muncul. Penelitia mengumpulkan lebih dari 3.7 juta artikel pada media public health issue. Setelah didownlaod mereka menggunakan metode cleaning unutk memilah artikel yang sesuai topik dan tidak sesuai termasuk hiperlink dan term yang berulang. menggunakan Apache Solr untuk informasi and idnexing. Menggunakan desktipsif statistik untuk mengukur coverage dari news media, juga menggunakan Google trends. Untuk sentimen analiss mereka menggunakan computarized algorithms. Untuk topik model menggunakan Topics Keyword Model (TKM) untuk mengidentifikasi hiden topic structures. Secara umum menggunakan tiga sentimen kateogris yakni positif, netral, dan negatif.
Ekspektasi professor untuk final project adalah mempresentasikan hasil analisis dari data aset yang sudah diberikan. Secara umum yang kita lakukan adalah menentukan pertanyaan penelitian, kemudian metode untuk analisis data, prosedur penelitian, dan text mining, penyajian hasil data, pembahasan dan komentari terhadap data yang dihasilkan, simpulan, referensi.
9. Content Analysis in Image (Tuesday, 23 November 2021)
Hari ini kami melanjutkan workshop text mining yang kedua. Seperti biasanya materi sudah disediakan oleh pemateri pada platform elearn. Hari ini topiknya masih lanjutan dari topik minggu sebelumnya. Pada bagian awal pemateri menjelaskan beberapa fungsi kode yang digunakan untuk mengatur pencarian kata yang kita butuhkan. Topiknya meliputi TOPIK MODEL yang meliputi load data, parameters, dokument feature seperti TF-IDF, TF, topic model seperti Non-Negative Matrix Factorization (NMF), Latent Dirichlet Allocation. Sayangnya saya tidak dapat memahami fungsi masing-masing fiture karena pemateri menggunakan bahasa Mandarin dalam menjelaskannya. Kemudian NLTK yakni library untuk tokensasi memilah kata yang bermakna dan menghilangkan stopword atau kata yang umum seperti dan, atau, jika, dan sebagainya. Materi berikutnya LDA (Latent Dirichlet Allocation) model yang banyak digunakan untuk kebutuhan text mining. Spacy library NLP untuk memudahkan kategorisasi, klasifikasi, tekenisasi dari text mining aplication termasuk library stopword sebagaimana fungsi library lainnya. Library ini dapat membedakan kata dari jenisnya seperti verb, ADJ, ADV sehingga ketika kita melakukan text mining kita dapat memisahkannya dari kata-kata lain yang kita cari untuk dianalisis.
10. Policy Research regarded COVID-19 (Tuesday, 30 November 2021)
Hari ini kami mendiskusikan empat paper yang dibahas oleh empat presenter, paper pertama berjudul: Mobilizing policy (in) capacity to fight COVID-19: Understanding variations in state responses disajikan oleh Jay. Paper ini membahas tentang bagaimana respons dari para pemerintah berkaitan dengan situasi darurat disebabkan COVID-19. Sayangnya agak sulit memahami sistematika paper, karena tidak jelas bagian pendahuluan, metode, hasil, pembahasan dan simpulan. Paper ditulis secara naratif deskriptif. Menggunakan topic modeling khususnya s structural topic model (Robert, et al, 2014). Ada 13 tema yang muncul seperti pembatasan perjalanan luar negeri, fasilitas kesehatan, karantina, kesadaran publik, budaya, dan lain-lain. Tidak ada tema tentang vaksin karena data set diambil dari Maret-Mei 2020. 18 perangkat kebijakan yang umum digunakan dalam merespon COVID-19, seperti tax payment deferal, tax relaxation, business loan, social distancing, health facilities, monetary policy, patient care, et all (OECD, 2020). Ada tiga level kebijakan yang diberlakukan yakni pada level individual, organization, and systemic. Tingkatan kapasitas model responnya ada yang tinggi dan ada yang rendah.
Paper kedua berjudul Health communication through news media during the early stage of the COVID-19 outbreak in China: digital topic modeling approach yang dipresentasikan oleh Sheila. Secara umum paper ini membahas tentang bagaimana media menyediakan informasi. Data set dari China media data base. Mulai Januari-Februari 2020 menggunakan wisesearch. Menggunakan LDA model penulis menyajikan data dan informasi. Dalam prosesnya meliputi pengumpulan data meliputi segmentasi, pemisahan redundant dan meaningless data, persiapan data dan pemrosesan data menggunakan LDA. Menggunakan Coherence Model dari Gensim. Mereka menggunakan statistical measure and manual interpretation dan memilih 20 topik untuk dianalis.
Paper ketiga berjudul Future studies: Reimagining our educational futures in the post-Covid-19 world paper ini dipresentasikan oleh .... . Secara umum paper ini membahas tentang pemikiran penulis mengenai masa depan pendidikan setelah periode pandemi tahun 2020. Penulis cukup kritis menganalisis masalah dan melihat masa depan yang tidak tergambar hari ini. Namun intinya manusia dan pelaku pendidikan harus siap dengan setiap perubahan. Dan pendidikan akan sangat dinamis, manusia harus pandai menyesuaikan dengan keadaan.
Paper keempat berjudul Impact of COVID-19 Pandemic on Taiwan International Higher Education Students' Mobility: Student Perspectives from Vietnam yang dipresentasikan oleh Jo. Secara umum paper ini membahas tentang bagaimana mobilisasi mahasiswa asing di tengah situasi pandemi, sampel penelitian terlalu kecil karena hanya melibatkan mahasiswa pada satu jurusan dan berasal dari satu negara yakni Vietnam. Selain itu dari masa studi yang lebih dari 2 tahun, agak sedikit aneh, jika mereka mau bertanya tentang pendapat setelah pandemi karena hanya 1 yang merupakan freshman. Intinya mahasiswa tidak dipengaruhi oleh pandemi. Mereka lebih mementingkan impiannya untuk studi di luar negeri (Taiwan). Namun menariknya jumlah mahasiswa asing yang studi di Taiwan meningkat daripada menurun. Misalnya dari Vietname meningkat sebesar 32% antara tahun 2019 ke 2020. Peneliti menggunakan push pull theory. Biasanya ada push factor (country of origin) dan pull factor (country of destination)
11. Text mining about COVID-19 (Tuesday, 07 December 2021)
Kuliah hari ini dimulai sharing singkat salah satu PhD studentnya professor, beliau sharing tentang tahap pemilihan model yang palign bagus untuk peneentuan analisis menggunakan LDA. Formulanya adalah pilih jumlah topik antara 11-17. Kemudian formula lainnya adalah menggunakan perhitungan dari perplexity dan coherence score, aturannya semakin kecil perplexity itu lebih baik dan semakin tinggi skore coherence itu juga lebih baik. Namun perlu juga dilihat sebaran plotnya, agar tidak ada kerapatan pada setiap topic untuk memisahkan masing-masing kelompok topik. Pembicara membagikan datasetnya dan meminta kami untuk memberikan penamaan. Setelah itu kamiemndiskusikan dengan kelompok kami.
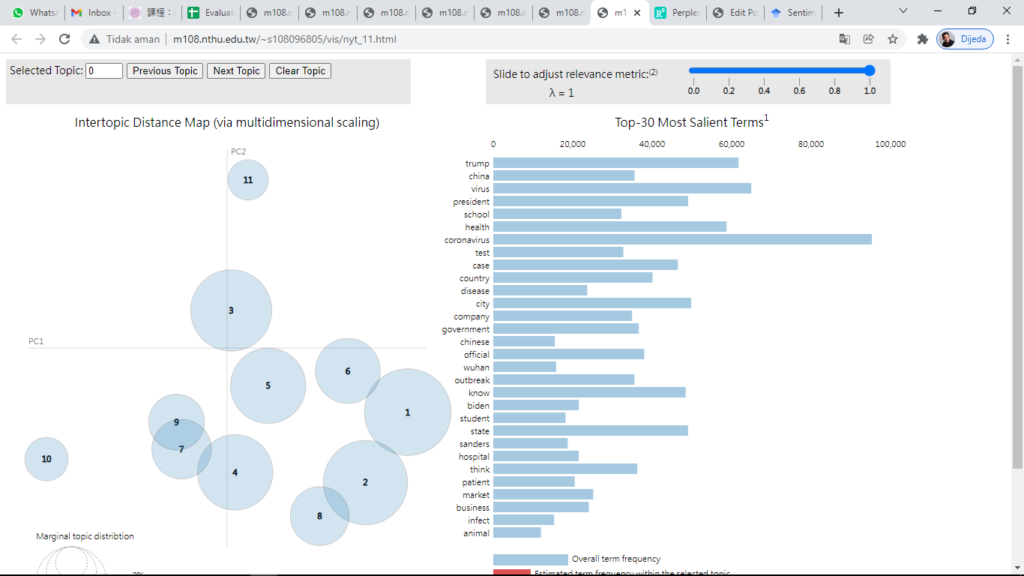
Agenda berikutnya adalah persentasi paper dari Ketty dengan jucul The contagion of sentiments during the COVID-19 pandemic crisis: The case of isolation in Spain. Paper ini menganalisis tentang sentimen analisis pada beberapa media sosial seperti News, twitter, youtube, online forum, dan formal press release dari pemerintah. Dimana data paling banyak didominasi oleh twitter lebih dari 82%. Secara umum ada emosi khawatir, takut, sedih, dan gelisah, namun pada saat yang sama ada rasa senang.
Paper berikutnya berjudul Sentiment analysis and emotion understanding during the COVID-19 pandemic in Spain and its impact on digital ecosystems dipresentasikan oleh Jay. Paper ini diteliti di Spain sama dengan paper pertama. Hal yang bagus dari paper ini dilakukan seperti review paper menggunakan kriteria inklusi dan eksklusi. mereka juga consider tentang fakepost, fake news, or bot post. ada empat jenis emosi yakni anger, fear, disgust, and sadness. Mereka mengugnaan Interval Majority Aggregation Operator (ISMA-OWA) untuk mengukur reliabilitynya. Hasilnya emosi publik berbeda dengan suara dari pemerintah.
Paper ketiga berjudul Discussion on People's View of Interests under the COVID-19 Pandemic yang dipresentasikan oleh John. Paper ini ditulis oleh peneliti bidang social dari salah satu univ di China. Paper ini menjelaskan tentang bagaimaan para pemikir China mengenai pentingnya menempatkan publik interest sebagai hal yang prioritas untuk dilakukan. Pilih majority of the people.
12. Workshop sentiment anaysis (Tuesday, 14 December 2021)
Kuliah hari ini dilakukan dalam bentuk workshop untuk mengenali sentimen analisis, pembicara kuliah seperti biasanya yang diundang pada dua workshop sebelumnya. Dan seperti biasanya saya tidak dapat mengikuti secara maksimal karena pembicara menggunakan bahasa mandarin dalam menjelaskan materinya. Materi workshop sudah diunggah di e-learn seperti biasanya.
Hari ini kami belajar tentang text entity, kemudian dasar-dasar untuk pengenalan sentiment analysis menggunakan library dari Google Cloud, sayangnya untuk menggunakan layanan tersebut kita harus memiliki kartu untuk pembayaran jika penggunaan kita melebihi 5k karakter. Berhubung kartu saya belum diaktivasi untuk hal tersebut sehingga tidak dapat digunakan. Mungkin besok siang saya mau ke bank dulu untuk proses aktivasi agar kartunya dapat digunakan untuk melakukan transaksi internasional.Tapi prinsipnya mengapa kita menggunakan Google Cloud karena lebih sederhana dan tersedia kamus bahasa sentimen yang lebih lengkap serta menyediakan kamus dalam berbagai bahasa. Secara umum konsep sentimen analisis ada tiga yakni negatif, netral dan positif. Negatif dari -1 sampai -0,25, netral dari -0,25 sampai 0,25, sedangkan positif dari 0,25 sampai 1. Itu rumus umum yang disepakati bersama. Setiap kata memiliki derajat masing-masing, sehingga kita dapat menghitung kadarnya apakah sangat positif, positif, netral atau sangat negatif. Tergantung dari kata-kata yang ditemukan. Hari ini juga kami mulai mendiskusikan untuk judul proyek final kami, sudah ada judul yang akan kami angkat, dan saya kebagian tugas untuk mencari literature review berkaitan dengan topik tersebut, kemudian menyiapkan slide untuk bahan tayang laporan akhir. Minggu depan kami akan rapat untuk membahas tugas. 4 minggu ke depan kegiatan akan sangat padat dengan tugas-tugas akhir yang sangat banyak dan rata-rata berupa proyek paper. Semoga diberikan kesehatan dan kelancaran, amin.
13. Diskusi Paper Text Mining (Tuesday, 21 December 2021)
Kuliah hari ini kami mendiskusikan 4 paper yang berhubungan dengan text mining dan content analysis. Kami juga belajar banyak tentang bagian metode yakni berkaitan dengan LDA dalam text mining dan sentiment analysis.
Artikel pertama berjudul Social media users' opinions on remote work during the COVID-19 pandemic. Thematic and sentiment analysis yang dipresentasikan oleh Sheila. artikel ini membahas tentang public opining berkaitan dengan work form home berdasarkan hastag yang muncul di twitter. Artikel menggunakan thematic and sentiment analysis. Secara umum terjadi polariasi opinion antara yang setuju dan yang tidak setuju. Karena kadang ketika kerja di rumah mereka akan terdistraksi oleh anak-anaknya.
Artikel kedua berjudul Comparing News articles and tweets about COVID-19 in Brazil: sentiment analysis and topic modeling approach yang dipresentasikan oleh Andy. Artikel ini menganalisis tentang public opinion berkaitan dengan COID-19 di Brazil. Ini artikel yang menarik berkaitan dengan proses LDA dan sentiment analysis. Sehingga kita dapat mengetahui apakah opini publik bersifat negatif, positif atau netral.
Artikel ketiga berjudul: #MaskOn! #MaskOff! Digital polarization of mask-wearing in the United States during COVID-19. Paper ini merupakan paper ketiga yang saya presentasikan, dan setelah paper ini saya merasa senang karena telah menyelesaikan tiga dari 4 tugas dari mata kuliah ini. Paper ini berisi kajian tentang polarisasi opini publik tentang penggunaan masker di US. Sangat menarik walaupun tidak mudah untuk mencerna isinya khususnya pada bagian metode. Penulis telah menggunakan kualitatif dan kuantitatif dalam menganalisis datanya. Ada 5 data sources yang dikaji, namun yang utama adalah hastags pada twitter.
Paper keempat brjudu Prediction of beauty and liking ratings for abstract and representational paintings using subjective and objective measures
Pada pertemuan ini juga professor memberikan hasil catatan komentarnya pada slide yang kami buat dan kami sajikan. Alhamdulillah dari dua tugas saya sebelumnya professor mengapresiasi slide dan presentasi saya dengan baik. Beliau memberikan nilai A+ dan apresiasi yang sangat baik. Semoga nilai akhirnya juga A+. Namun apa pun itu hari ini saya merasa senang karena saya telah menyelesaikan tiga tugas presentasi saya. Dan saya bisa fokus pada tugas liannya yang belum selesai.
14. Diskusi Paper Text Mining and Sentiment Analysis (Tuesday, 28 December 2021)
Hari ini kami memasuki pertemuan terakhir untuk presentasi paper secara individual, ada empat paper yang dipresentasikan. Biasanya professor memulai kuliah dengan memberikan pengantar dan ulasan dari setiap paper, namun kali ini professor memberikan kesempatan pesenter pertama untuk mempresentasikan dulu papernya, kemudian beliau masuk untuk memberikan pengantar. Paper pertama berjudul Investigating COVID-19 News Across Four Nations: A Topic Modeling and Sentiment Analysis Approach yang dipresentasikan oleh Fany. Paper ini mendiskusikan tentang hubungan kasus Covid-19 dengan news pada empat negara yakni Japan, UK, South Korea and India. Peneliti melakukan analisis LDA and sentyment analysis dari keempat data dari keempat negara. Peneliti melakukan pencarian apda top 10 topic kemudian mengkomparasikannya dengan hasil dari setiap negara termasuk bagaimana sentimennya. Sosial media dewasa kini telah menggiring kemunculan opini publik secara masif. Kita dapat melihat jenis emosi publik melalui sosial media. Diperlukan kajian untuk memotret fenomena tersebut.
Paper kedua berjudul Explaining the media's framing of renewable energies: an international comparison yang dipresentasikan oleh Andy terbit tahun 2019 di Jurnal of Frontiers in Environmental Science. Pada artikel ini penulis menganalisis artikel tentang renewable energies dari 11 negara antara lain Australia, New Zealand, USA, Canada, Great Britain, Austria, Germany, South Korea, India, and Indonesia. Menarik karena author berani masuk ke negara non english country seperti German dan Indonesia. Mereka menggunakan seminal hierarchical influences model by Shoemaker and Reese (1991, 2014). Penulis juga mengkomparasikan persepsi publik sebelum dan sebelum peristiwa Fukusima (ledakan nuklir). Teori framing dari Entman (1993) tentang bagaimana media mempromosikan suatu isu. Ada beberapa framing topic antara lain ekonomi, teknologi, lingkungan dan society yang berhubungan dengan RE.
H1: Dinegara yang lebih banyak penggunaan energi konvensional seperti dari batu bara dan nuklir maka framing RE akan cenderung negative, sedangkan di di negara yang lebih banyak menggunakan RE maka akan cenderung positive. H4: Setelah peristiwa Fukusima maka framing mendia lebih positif dibandingkan sebelumnya. Menggunakan LexisNexis database dalam mengkumpulkan data artikel tentang berita. Ada empat jenis RE yang dicari yang dicari yakni hydropower, wind power, solar energy, and geothermal energy. Ada empat frame yakni ekonomi dan teknologi, lingkungan dan social evaluation. Ada 3 hipotesis yang diterima dan ada dua hipotesis yang ditolak.
Paper ketiga berjudul Hostile emotions in news comments: A cross-national analysis of Facebook discussions yang dipresentasikan oleh En-Yi. Paper ini ditulis oleh Edda Humprecht, Lea Hellmueller, and Juliane A. Lischka. Paper ini membahas tentang hostile emotion in facebook comments. Paper ini masih berhubungan dengan polarization yang saya jelaskan minggu lalu. Konteksnya dilakukan di US dan German. Dataset 244.562 user coments and post 1.438 dalam satu minggu in tahun 2017. US comment (0.66) is hostile comment than German comment (0.48). Penulis juga meuliskan top 10 main topic per country. Di US komunikasi politiknya lebih ke heated electoral dibandingkan di German yang lebih Balanced disebabkan karena perbedaan kultur masyarakat.
Paper keempat berjudul An investigation of the role of article commendation and criticism in Taiwanese university students' heavy BBS usage yang ditulis oleh Barry Lee Reynolds (Yangming-Macau), and Siou-Lan Wang (NCU) dan dipresentasikan oleh Sherry Hong. Paper mengkaji tentang PTT (Professional Technology Template) and BBS and ACAC. Ada dua term yang diakji yakni non academic gossip dan academic education. pada ACAC scheme ada tiga yakni commendation, Criticism and neutral.
Minggu depan adalah pertemuan terakhir dari mata kuliah ini, kami diberikan waktu untuk presentasi selama 40 menit kemudian diskusi selama 10 menit. Kami harus menyelesaikan final project h-1. Kami diberikan kebebasan untuk melakukan analisis apakah hanya menggunakan LDA atau termasuk sentiment analysis. Mengingat data kami hanya sedikit, akhir kami hanya menggunakan LDA, semoga dapat skor yang maksimal dari final project kami.
15. Presentation Group Final Project (Tuesday, 4 January 2022)
Alhamdulillah hari ini kami sampai dipenghujung semester untuk mata kuliah NLCATM, saya sangat senang karena pada akhirnya dapat melewati semua tahap dalam suka dan duka. Saya dapat mengerjakan 3 paper presentasion dan pada bagian akhir mengerjakan dan mempresentasikan final project. Project kami berjudul Comparing News about Education in Pandemic Covid-19 in US: A topic modeling and sentiment analysis. Kami melakukan analisis data menggunakan Phyton, LDA dan sentiment analysis, ini pengalaman baru bagi saya, walaupun saya lebih banyak dalam proses kalkulasi data, deskripsi data, dan pengembangan chart dan figure serta analisis hasil olahan data. Sangat senang dan menarik dengan pengalaman dari mata kuliah ini. Selain itu kami juga dapat menganalisis dan mengolah data lebih jauh untuk menulis paper dikemudian hari.
Kelompok dua mengkaji dari sisi government policies, sedangkan kelompok tiga membahas tentang isu penggunaan masker. Kami menggunakan data set dari NYT dan WST. Kami dari kelompok satu menggunakan LDA and sentiment analysis sehingga kami harus membayar biaya cukup mahal ketika menggunakan data dari Google Cloud dictionary, total biaya yang harus kami bayar sekitar 20.000 atau 10,1 juta. Namun alhamdulillah dosen akan membayari biaya yang kami keluarkan. Sementara itu kelompok 2 dan 3 lebih banyak fokus menggunakan LDA. Lalu mendeskripsikan hasilnya. Namun kami menggunakan pertanyaan penelitian dan isu yang berbeda. Saya bertanya kepada kelompok 3 tentang rel_value, maknanya dan skor yang mana yang paling baik, kemudian kami bertanya tentang perbedaan LDA dan manual classification, mana yang paling mudah dan efektif, serta mana yang paling akurat,
Pada akhirnya saya mau menyampaikan terima kasih kepada prof yang telah mengajar, TA yang telah memfasilitasi dan pembicara pada workshop yang kami lakukan, serta teman kelas dan teman kelompok, saya sangat senang dengan perjalanan dari kuliah semester ini. Juga tidak lupa saya sampaikan terima kasih kepada diri sendiri karena telah mau berjuang, bersusah payah dan berani mengambil resiko untuk mengarungi samudera ilmu pada dimensi yang baru dari yang biasa saya pahami. Juga terima kasih saya sampaikan kepada keluarga, istri dan anak-anak atas pengertiannya karena semester ini banyak waktu yang terlewati disebabkan kebutuhan untuk fokus pada tugas kuliah yang cukup menyita. Semoga ilmunya berkah dan bermanfaat untuk saya dan orang-orang yang menikmati karya saya berkaitan dengan mata kuliah ini ke depannya. Alhamdulillah nilai mata kuliah ini dapat A+. Semoga berkah ilmunya.
Hsinchu, 4 January 2022, jam 12.00
Komentar
Posting Komentar
You can give whatever messages for me,,